news recommendations - a context tree approach
An important proportion of news website traffic is generated by casual readers following links found in social media or search results. Capturing the attention of those readers is important for publishers as an increase in page views by session has a direct impact on ad revenue. Implementing a recommender system is a possible way to achieve this objective.
Recommender systems are today very popular, especially in commerce websites. The examples of Amazon or Netflix are well known and have even been covered in the non-specialist press.
Generating recommendations for news website is, to some extent, more challenging. The fact that most readers consume news anonymously makes it difficult to learn their preferences. Also, the speed at which news items are becoming obsolete has to be dealt with. Despite those challenges, publishers are developing recommender systems and some of them are reporting about their successes: New York Times, Washington Post.
Most of the recommender systems are based on a combination of two possible approaches to recommendations: Content based recommenders use similarity between the content of the page currently visited and the content of other pages to make recommendations. Collaborative filtering systems infer user preferences and make recommendations based on what similar users visited. (More details…)
The recommender covered in this post is based on the Context Tree approach described in a paper by Garcin et al. [1] and relies on user behaviours to generate recommendations. This recommender is the first one developed by our organisation and alternative approaches are tested in parallel. Our objective is to learn what approaches work best for different sections of our website or for different audiences. We already know that future solutions will be based on a variety of recommenders working together to enhance the experience of our readers.
We base our recommendations on journeys - or sequences of pages visited on our website. We start by capturing all the journeys made by our users and we organise them in a tree structure. We call that data structure Context Tree. Every time a user is visiting a new page on our site, we either add a branch to the tree and initialise a counter recording how many visitors reached that node, or we find a matching branch in the tree and increment the existing counter.

Recommendations are then simply based on where visitors who reached a node in the tree are more likely to go next. Take a visitor with journey {Page 1; Page 2}. We would recommend to that user to visit page 3 with probability 0.5 (2/4), page 4 with probability 0.25 (1/4) and page 5 with probability 0.25 (1/4).
As illustrated in our example, it might not always be possible to retrieve enough recommendations for a match based on a full journey. To work around this limitation, we recursively retrieve recommendations for all the suffixes of the journey. We obtain the suffix of a journey by removing its first page. In our example, the only suffix of journey {Page 1; Page 2} is {Page 2}. Based on that suffix, we would also recommend page 6 (probability 3/7) and page 7 (probability 4/7).
Weights are used when recommendations are generated from different suffixes. The idea is to give more importance to recommendations based on the full journey compared to recommendations based on suffixes. To do so, we attribute decreasing weights to each subsequent suffix. In our example, we could use a weight of 2/3 for the full journey and a weight of 1/3 for the first suffix - we want our weights to sum to 1. The rate at which weights decrease from one level to the next is a parameter of our model. In this example, it is set to 0.5. The table below shows how our final recommendations would be built.
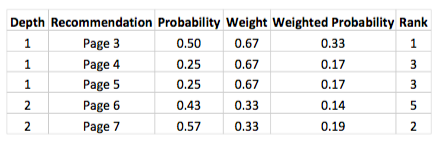
Note that in this made up example, Page 7 would be recommended before Page 4 based on its weighted probability.
In this post, we have introduced the process of capturing a user journey and making a recommendation separately to better explain the logic of our recommender. In practice, a single API is updating the tree and returning recommendations.
So, how is it working so far? We started to test the recommender described in this post on our website. The first results are showing a significant increase in Click Through Rate (CTR) compared to a baseline where a list of “most read” articles is displayed in the same position on the page. These first results are quite encouraging and should help us to move towards our objective of increasing user engagement.
Obviously, this is only the beginning of our journey. We still work on improving this first recommender and explore other ways to make recommendations based on a context tree. We also work in parallel on recommenders based on similarity of content. Hopefully, a future post will share more details on our progresses and will show how this recommender compares to other approaches.
[1] F. Garcin, C. Dimitrakakis, and Boi Faltings. “Personalized news recommendation with context trees.” Proceedings of the 7th ACM conference on Recommender systems. ACM, 2013.
Herve Schnegg
... solving business problems with data
